
Stop Training Your LLM Router: Zero-Shot Confidence Beats Supervised Baselines
Published:
TL;DR: We tested whether you actually need labeled training data to route queries between a cheap local LLM and an expensive cloud model. You don’t. Average token log-probability — available for free from the first query — matches supervised routing in-distribution and crushes it when the query distribution shifts. We tested across 3 model families, 2 datasets, ~4,500 queries, and $123 in cloud costs. All code and data are open.
The Problem
You’re running a 7B model locally. It’s cheap but gets things wrong 40-70% of the time. You have access to a cloud model (Claude, GPT-4) that’s much better but costs money per query. The question: which queries should you send to the cloud?
The standard answer is supervised routing. Train a classifier on labeled examples — “this query the local model got right, this one it got wrong” — and use it to predict which future queries need escalation. RouteLLM popularized this approach.
The problem: it requires labeled data. You need to run both models on a representative corpus, judge correctness, and train a classifier. For our experiments, that cost ~$25 and 2 hours per model. And there’s a deeper problem we discovered: supervised routers learn properties of the query distribution, not properties of the model. When the queries change, the router breaks.
What We Tested
We compared four zero-shot confidence signals against RouteLLM-style supervised baselines:
- Log-probability (logprob): How surprised was the model by its own output? Average per-token log-probability, mapped to [0,1] via sigmoid.
- Self-assessment (GSA): Ask the model “Are you confident?” and extract the YES/NO probability from logprobs.
- Self-consistency: Generate two answers and measure overlap.
- Knowledge similarity: How close is the query to things in a knowledge base?
We tested on three 7-8B models (Qwen-2.5-7B, Llama-3.1-8B, Mistral-7B) across two datasets (MMLU-Pro and TriviaQA).
The Key Finding
Logprob wins. Everywhere.
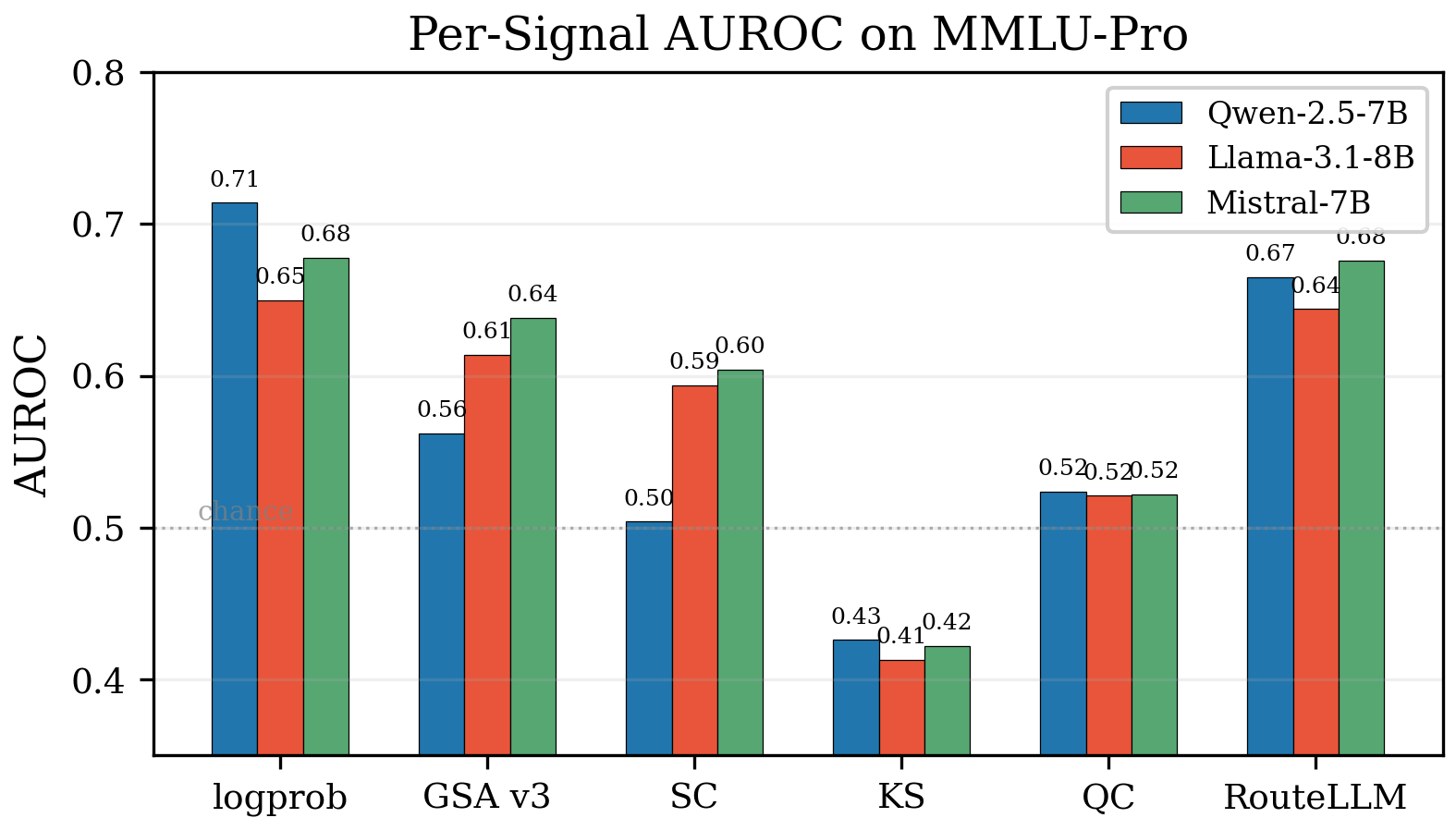
On MMLU-Pro (in-distribution for the supervised baseline):
| Signal | Qwen | Llama | Mistral |
|---|---|---|---|
| logprob (zero-shot) | 0.714 | 0.650 | 0.678 |
| RouteLLM (supervised) | 0.665 | 0.644 | 0.676 |
Logprob matches or beats the supervised baseline on every model — with zero training data.
But the real story is what happens when the query distribution shifts. We trained RouteLLM on MMLU-Pro (multiple-choice questions) and evaluated on TriviaQA (open-ended trivia):
| Signal | MMLU-Pro | TriviaQA |
|---|---|---|
| logprob | 0.681 | 0.782 ↑ |
| RouteLLM | 0.662 | 0.546 ↓ |
RouteLLM collapses to near-chance on a new dataset. Logprob actually improves. This isn’t a fluke — it’s structural.
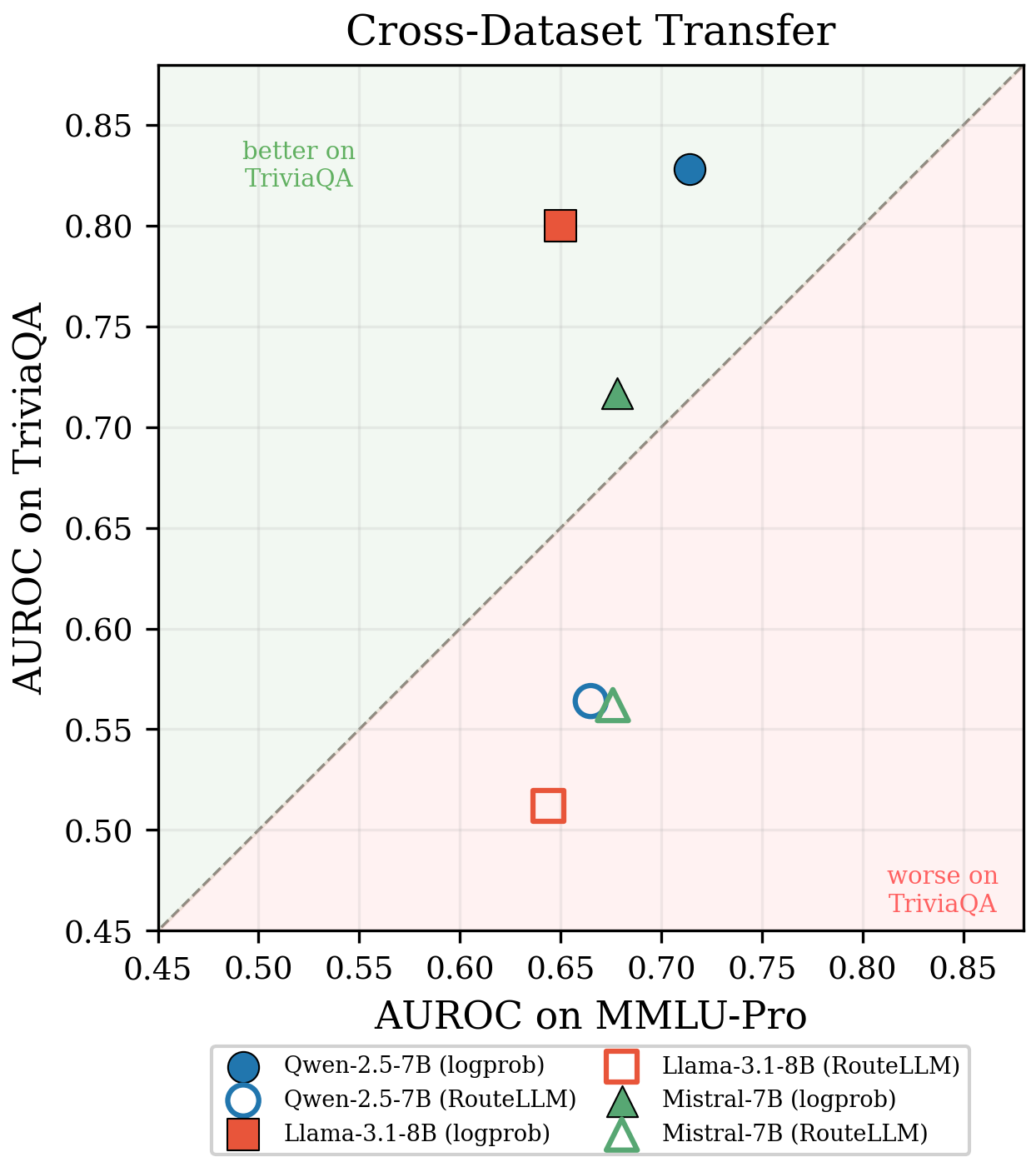
The supervised router learned “which MMLU-Pro questions are easy,” not “which questions this model can answer.” Logprob measures the model’s own token-level surprise, which doesn’t depend on the query distribution at all.
Why This Happens: Query-Side vs. Generation-Side
This is the conceptual distinction that explains all our results:
- Query-side signals (supervised routing): Learn a mapping from the input to difficulty. Breaks when the input distribution changes.
- Generation-side signals (logprob, self-assessment): Measure properties of the model’s output. Transfer because they don’t depend on the input.
It’s the difference between “I’ve seen questions like this before and they were easy” vs. “I just generated this answer and I was confident about every token.”
The Supervised Learning Curve: More Data Doesn’t Help
We trained RouteLLM with 25, 50, 100, 250, 500, and ~1000 examples. It’s wildly unstable at small N (AUROC swings of 0.27 between models at N=25), converges around N=250, and at convergence never exceeds the zero-shot logprob line.
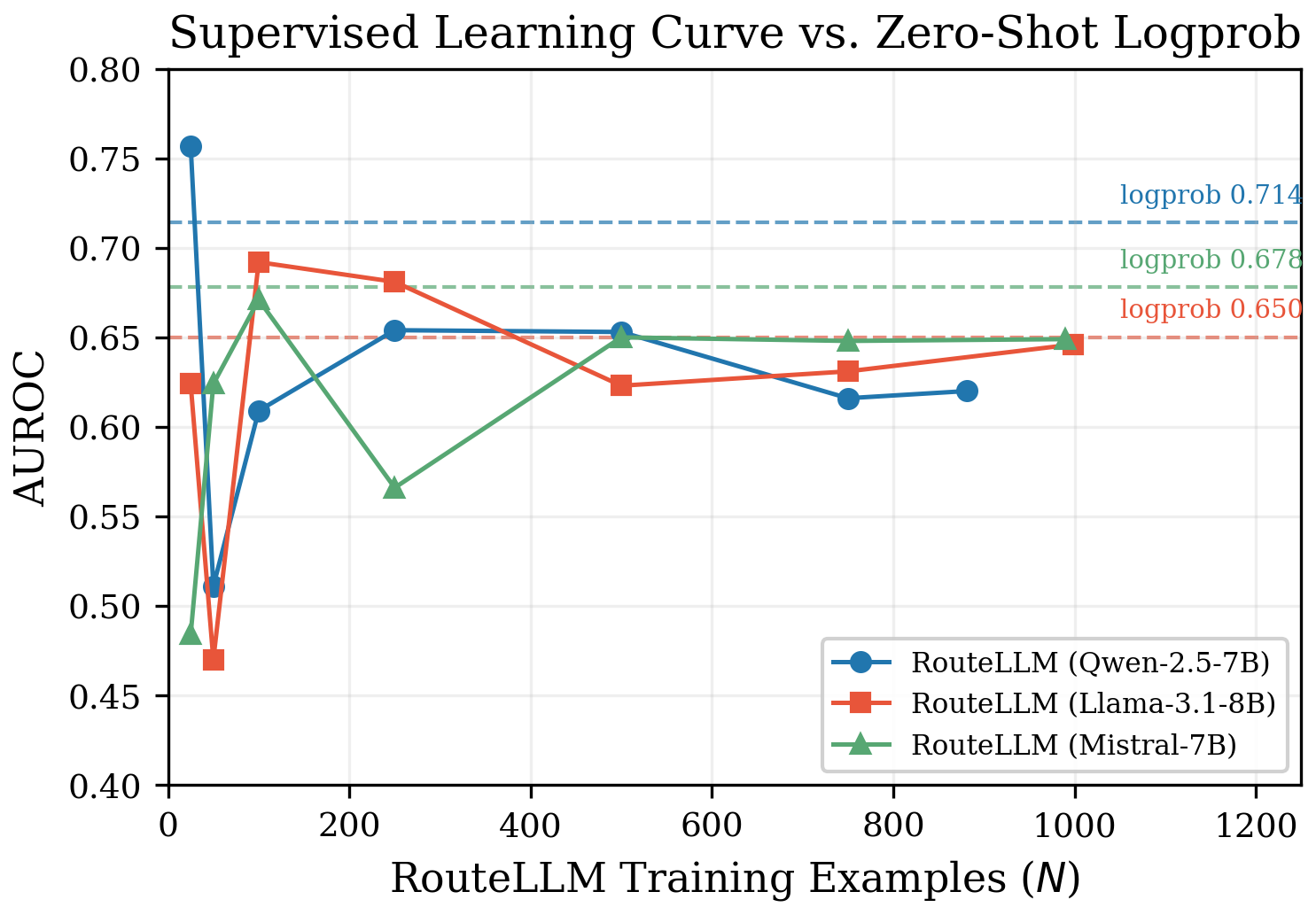
You can spend $25 and 2 hours training a router that performs no better than a free signal — and that router won’t transfer to a new domain.
Retrieval-Conditional Self-Assessment
We also proposed a new pre-generation signal: retrieval-conditional self-assessment (GSA v3). The idea: before generating an answer, ask the model “are you confident?” — but selectively inject retrieved knowledge when strong matches exist.
The key design insight: never reveal retrieval absence. If the knowledge base has nothing relevant, fall back to a prompt byte-identical to the no-retrieval version. The model can’t tell the difference between “retrieval found nothing” and “retrieval was never attempted.” This prevents the model from being primed toward “no” by the absence of context.
This improved self-assessment by up to +0.069 AUROC at 3-10× lower latency than logprob (~500ms vs 1.5-4.8s). It’s useful as a cheap pre-generation filter: escalate immediately if the model isn’t confident, saving the cost of full generation.
What Should You Deploy?
| When | Signal | AUROC Range | Cost | Latency |
|---|---|---|---|---|
| Day 0, no data | logprob | 0.650–0.833 | $0 | 1.5–4.8s |
| Day 0, latency-sensitive | GSA v3 | 0.562–0.720 | $0 | 0.5–0.8s |
| After labeling ~1000 queries | RouteLLM | 0.620–0.676 | ~$25 | <1ms |
Start with logprob. It’s free, it works from the first query, and it transfers across domains. If you need pre-generation routing (to avoid wasting compute on full local generation), add GSA as a first-stage filter.
RouteLLM training is only justified when: (a) your query distribution is known and stable, (b) you need sub-millisecond pre-generation routing, and (c) you’ll never face a new domain.
Reproducibility
Everything is open:
- Paper: arxiv.org/abs/2605.02241
- Code + data: github.com/BuffaloTechRider/zero-shot-llm-confidence-estimation
- Total cost to reproduce: $123
- Hardware: Single laptop + Ollama + AWS Bedrock
You can verify every number in the paper in 5 minutes using the included SQLite database, without running any models.
Luong N. Nguyen — May 2026